Some background
You may know that image classification models are generally invariant to visual details such as brightness, object pose, or background configuration. For example, if we are classifying animals, models don’t care whether it’s a white poodle or a black puppy - both will be recognized simply as a dog. In other words, classification models discard most information about the image other than what is necessary to predict its class.
In this paper, the authors try to reconstruct images from the logits of a classification model. Earlier work has already attempted to invert logits back into images, but in this article they propose a more effective way to generate images using conditional BigGAN (more about the generation process below).
How can we invert logits to image?
Methods developed to invert representations in classification networks generally fall into two categories: optimization based and learning based.
Optimization based
This method just uses backpropagation to find the image $x \in \mathbf{R}^{H \times W \times C}$ that minimizes the loss:
\[\mathcal{L}(x, x_0) = \Vert\Phi(x) - \Phi(x_0)\Vert_2 + \lambda \mathcal{R}(x)\]where $x_0$ is the original image, $\mathcal{R}$ is a prior function and $\lambda$ is a hyperparameter.
Optimization-based methods offer a training-free, model-agnostic way to probe and interpret learned representations.
But the drawbacks are clear: the generated image strongly depends on the random initialization, and the method is slow and computationally expensive.
Learning based
Learning-based methods use a training set of {logits, image} pairs to learn a decoder network that maps a logit vector to an image. In this work, the decoder is implemented as a generator, which produces an image from raw logits and some random noise. This is the approach used in the paper.
Experiment
Now let’s look at the scheme of the experiments conducted by the authors.
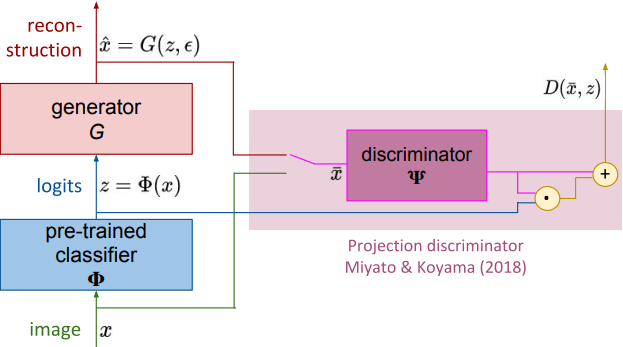
Here we have 3 model: a classifier $\Phi$, a generator $G$ and a discriminator $D$.
- Classifier
It’s just a pre-trained image classifier (in this paper, ResNet and Inception are used), but instead of a final label it outputs raw logits $z = \Phi(x)$.
- Generator
The generator takes raw logits $z$ and some random noise $\epsilon$, and produces an image $\hat{x} = G(z, \epsilon)$.
- Discriminator
Discriminator takes an image $\bar{x}$ (a real image $\bar{x} = x$ or an image $\bar{x} = \hat{x}$ generated by generator $G$) and outputs a real value $d = D(\bar{x}, z)$. If the image $\bar{x}$ is real then $d \gg 0$. If the image is synthetic then $d \ll 0$.
How It Works
Let’s understand how this setup works and why it answers the main question of the article.
The classifier $\Phi$ is fixed, so we only train the generator $G$ and discriminator $D$.
The discriminator trains to minimize:
\[\mathcal{L}_D = \mathbf{E_{x, \epsilon}}[\max(-1, D(G(z, \epsilon), z)) - \min(1, D(x, z))]\]Basically it means that we teach discrimantor to output positive value if it gets a real image and negative value if it gets a generated one.
The generator trains to minimize:
\[\mathcal{L}_G = -\mathbf{E_{x, \epsilon}}[D(G(z, \epsilon), z)]\]In other words, the generator learns to create such images that the discriminator will classify as real, essentially trying to fool it.
Thus, after training, we obtain a generator that can produce a realistic (or at least similar to real) image purely from raw logits.
Results
Example of reconstructions
Let’s look what the authors got from our trained generator.

Here are images generated from logits for different pre-trained classifiers. You can see that reconstructed images look surprisingly similar to the original ones.
Notice that the authors used different classifiers, Inception, and the robust and non-robust versions of ResNet.
ResNet reconstructions stay closer to the original image, while Inception outputs look more realistic.
Also the authors compare their architcture to the method of Dosovitskiy and Brox (2016), which fails in recovering object shape and details. For example, you can see that the rabbit here is just a fuzzy blur.
Visualizing Model Invariances
Besides reconstructing images, the authors also use the generator to visualize which properties of the image the classifier is invariant to.
The generator takes as input Gaussian noise in addition to the logit vector from classifier.
The noise affects non-semantic properties - shape, pose, size, position, showing which aspects are not encoded in the logits themselves.

Noise resampling for Robust ResNet. The top left images are the original ones.

Noise resampling for non-robust ResNet. The top left image are the original ones.
Notice how noise has a greater effect on the non-robust model than on the robust model.
Reconstruction of incorrectly classified images
What happens if we reconstruct an image from logits that corresponds to an incorrect prediction? Surprisingly, the reconstructed image still looks like the original:

Logit manipulations
What happens if we manipulate the logits themselves? The authors perform three types of modifications:
- logit shifting - adding a constant to each logit
- logit scaling - multiplying logits by a constant
- logit perturbation - adding Gaussian noise

In (a), for the robust model, shifting mainly affects contrast and sharpness, but also subtly changes shape. For example, in the hockey scene, three players gradually merge into one with larger shifts. In the non-robust model, the effect is much weaker.
In (b), scaling logits in robust models changes sharpness and contrast. In non-robust models there are fewer brightness changes, but the content itself starts to shift (e.g., the coral reef changes shape).
In (c), perturbing logits with Gaussian noise affects image content in both robust and non-robust models. For robust models, content changes are moderate; for non-robust models, noise changes the image much more dramatically, suggesting that their logits are more closely clustered in the output space.
Conclusion
We discussed that one can reconstruct remarkably accurate images from logits hat often look very close to the originals. Earlier we believed that classifiers discard irrelevant information. But in reality, the final logits contain more than just class-related features.
Even when the classifier gives incorrect prediction, we still manage to reconstruct an image similar to the original!
Also we discovered how logit manipulations affect reconstructed images. For robust ResNet-152, logit shifts and rescaling influence both contrast, sharpness and brightness, while for the non-robust model these manipulations have much stronger effects on the image content, highlighting how robustness affects the stability of reconstructed images.
Surprisingly, logits preserve more than just class information; they retain enough detail to reconstruct the original image, even though networks are expected to be invariant to differences among instances of a class.