Some background
Hyperparameter Optimization (HPO) remains one of the most resource-intensive bottlenecks in the machine learning pipeline. While the community has largely moved past Grid Search, the standard alternatives — Random Search and Bayesian Optimization — still suffer from a fundamental inefficiency: they treat the training process as a “black box” that must be run to completion.
In 2018, Lisha Li and researchers from Carnegie Mellon, Google, and the University of Washington published the paper “Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization.” They proposed a paradigm shift: instead of trying to intelligently select configurations (as Bayesian methods do), we should focus on efficiently evaluating them using adaptive resource allocation.
In this post, we will deconstruct the Hyperband algorithm, the theoretical problem it solves, and why it often outperforms Bayesian methods.
The Core Problem: The “n vs. B/n” Tradeoff
The central challenge in random search-based HPO is resource allocation. Suppose you have a total finite budget $B$ (e.g., total GPU hours). You need to decide how many unique hyperparameter configurations $n$ to evaluate.
This creates a fundamental tradeoff:
- Maximize $n$ (Width): You sample many configurations to cover the search space, but each gets a very small average budget ($B/n$).
- Risk: You might stop a promising configuration too early (“false negative”).
- Minimize $n$ (Depth): You sample few configurations, but train them to convergence.
- Risk: You train a poor configuration for too long, wasting resources that could have been used to explore other areas of the search space.
For a fixed budget, it is impossible to know which strategy — width or depth — will yield the best model. Hyperband was designed specifically to solve this dilemma.
The Building Block: Successive Halving
To understand Hyperband, one must first understand its subroutine: Successive Halving (SH). Originally proposed for multi-armed bandit problems, SH operates like a tournament:
- Initialize: Start with $n$ randomly sampled configurations.
- Evaluate: Allocate a small budget $r$ (e.g., 1 epoch) to all configurations.
- Select: Rank them by validation loss and discard the worst half.
- Promote: The surviving configurations are promoted to the next round with a larger budget.
- Repeat: Continue until one configuration remains.
While SH is efficient, it still requires the user to choose $n$. Given some finite budget $B$, if $n$ is too large, the initial budget $r$ might be too small to distinguish good models from bad ones. If $n$ is too small, SH behaves like standard Random Search.
The Hyperband Algorithm
Hyperband acts as a “wrapper” or an outer loop around Successive Halving. Instead of forcing the user to guess the optimal $n$, Hyperband iterates through different feasible values of $n$ for a fixed total budget.
It divides the total budget into several “brackets” (instances of Successive Halving):
- Most Aggressive Bracket ($s = s_{max}$): Starts with the maximum possible number of configurations ($n_{max}$) with the minimum resource per config. This is designed to identify “fast learners” quickly.
- Intermediate Brackets: Gradually decrease $n$ and increase the initial resource $r$.
- Most Conservative Bracket ($s = 0$): Starts with a small number of configurations but allocates the maximum resource immediately. This is essentially equivalent to standard Random Search (exploration) or simply training to convergence (exploitation).
Algorithm Inputs
Hyperband is notably easy to configure, requiring only two inputs:
- $R$: The maximum amount of resource that can be allocated to a single configuration (e.g., 100 epochs, or the full dataset size).
- $\eta$: The proportion of configurations discarded in each round of Successive Halving.

By iterating through these brackets, Hyperband performs a geometric search over the trade-off between “number of configurations” and “resource per configuration.”
Theoretical Framework: The Infinite-Armed Bandit
The authors frame HPO as a non-stochastic infinite-armed bandit problem.
- Infinite-armed: The hyperparameters are drawn from a continuous probability distribution.
- Non-stochastic: The algorithm does not make strong assumptions about the convergence curves of the loss functions.
This theoretical grounding is significant because it contrasts with Bayesian Optimization (BO). BO relies on fitting a probabilistic model to the function $f(x)$. In high-dimensional spaces, fitting this model becomes computationally expensive and often inaccurate. Hyperband avoids this complexity entirely by relying on principled random sampling and aggressive early stopping.
Empirical Results
The paper presents extensive evaluation comparing Hyperband against Random Search, SMAC, TPE, and Spearmint (popular Bayesian optimization frameworks) on several benchmarks.
1. Deep Learning (Iterations as Resource)
In this experiment, the authors tuned Convolutional Neural Networks (CNNs) on datasets like CIFAR-10 and SVHN. The resource budget was defined as the number of training iterations (epochs).
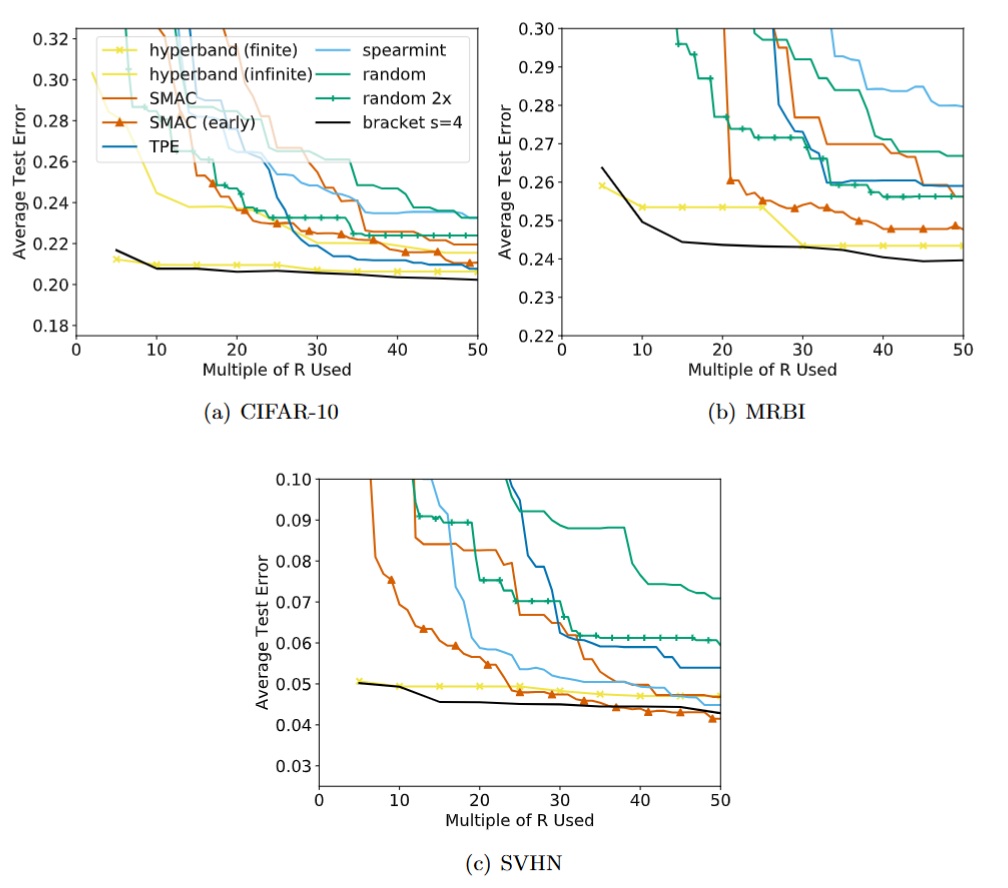
Average test error across 10 trials. Label “SMAC (early)” corresponds to SMAC with the early-stopping criterion and label “bracket s = 4” corresponds to repeating the most exploratory bracket of Hyperband. Result: Hyperband found high-quality configurations 5× to 30× faster than Bayesian methods.
2. Kernel Methods (Data Subsampling as Resource)
Here, the task was Kernel Least Squares classification. The resource was the size of the dataset subsample.
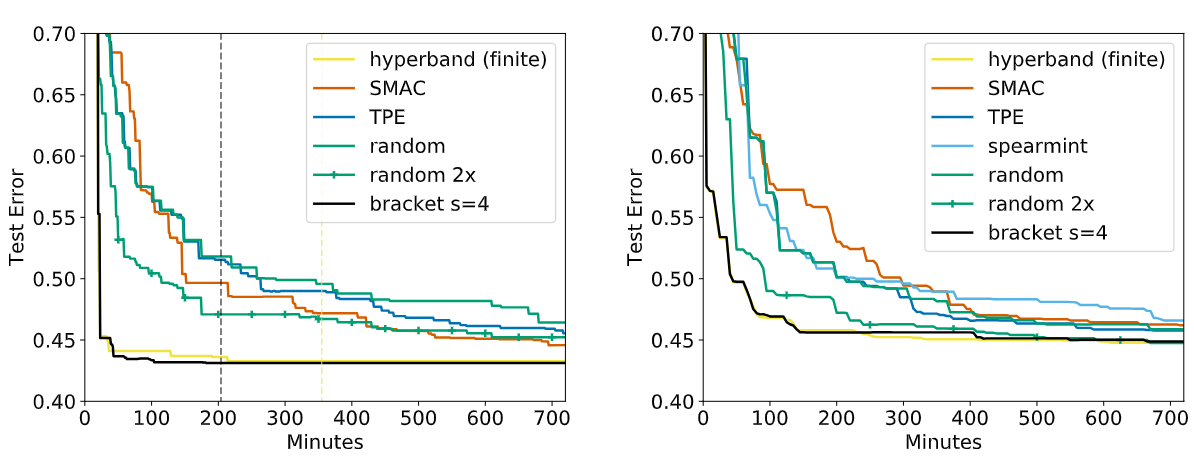
On left: Average test error of the best kernel regularized least square classification model found by each searcher on CIFAR-10. On right: Average test error of the best random features model. Result: Hyperband achieved a massive 70× speedup over Random Search.
3. Generalization (117 OpenML Datasets)
To test robustness, Hyperband was evaluated on a large-scale automated machine learning task involving 117 real-world datasets from OpenML.
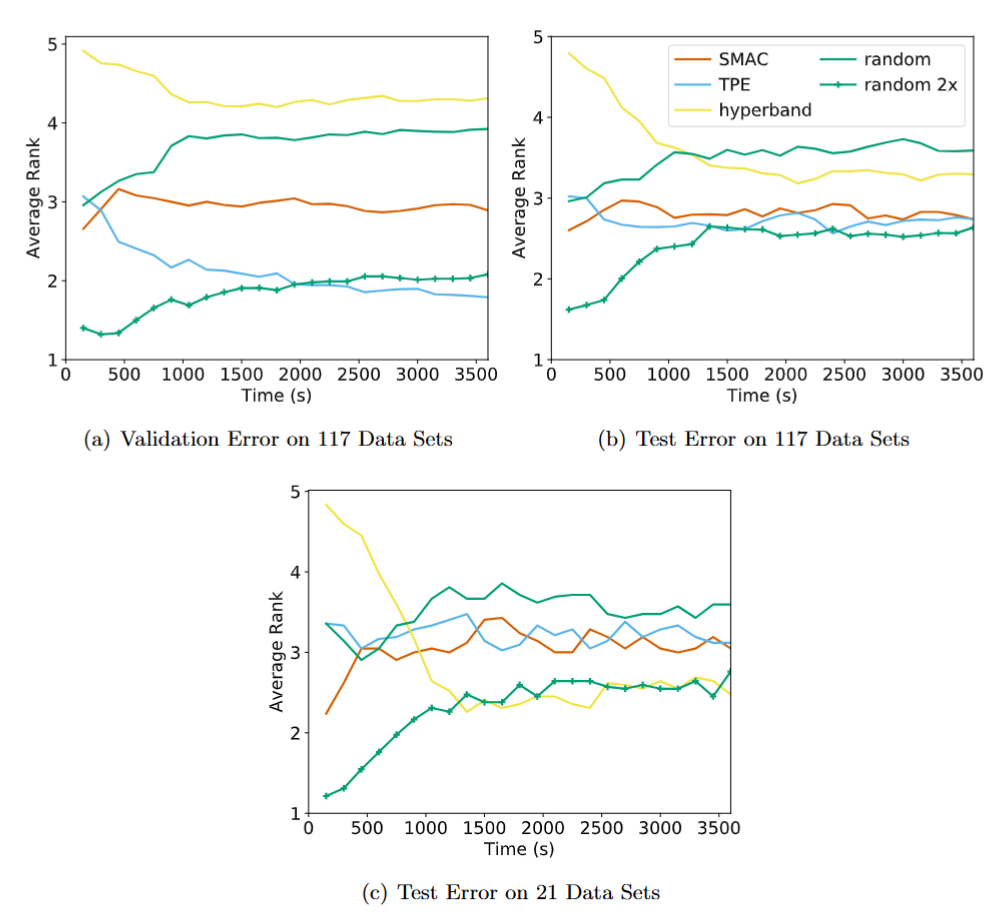
Average rank across all data sets for each searcher. For each data set, the searchers are ranked according to the average validation/test error across 20 trials.
- Avoiding Overfitting: A key finding was that Bayesian optimization methods often “overfit” the validation set — they found configurations that looked good during search but performed worse on the test set. Hyperband, being closer to Random Search in its sampling strategy, showed better generalization.
- Cost vs. Benefit: On a subset of 21 datasets where subsampling yielded meaningful computational speedups, Hyperband was the clear winner. However, on very small datasets where training takes seconds, the overhead of Hyperband made it less effective than simple Random Search.
Conclusion
The Hyperband paper provides a compelling argument that in the era of expensive model training, adaptive resource allocation is more critical than adaptive configuration selection.
Key Practical Takeaways:
- Efficiency: For problems where partial training (e.g., few epochs) correlates with final performance, Hyperband is superior to standard Random Search and often beats Bayesian Optimization.
- Simplicity: It requires minimal tuning compared to the complex kernels and acquisition functions of Gaussian Processes.
- Parallelism: The algorithm is easily parallelizable, making it ideal for modern distributed computing clusters.
Today, Hyperband has become an industry standard, available in major HPO frameworks such as Ray Tune, Optuna, and Scikit-learn (HalvingRandomSearchCV). For anyone dealing with computationally expensive model tuning, it is a valuable tool in the machine learning toolkit.