Multiobjective Tree-Structured Parzen Estimator (MOTPE): Bayesian Optimization for the Real World
Introduction: The Problem with Real-World Problems
Many of us are familiar with optimizing a single metric, like minimizing the error rate of a machine learning model. However, real-world problems are rarely that simple. They often involve juggling multiple, conflicting objectives simultaneously.
Real-world examples:
- Neural Network Design: High accuracy vs. low inference time (faster predictions).
- Mechanical Engineering: Maximum power vs. minimum fuel consumption.
- Cloud Computing: Low cost vs. high performance.
These objective functions are often:
- Expensive to evaluate (each evaluation takes hours or days).
- Black-box (no simple mathematical formula).
- Defined on complex search spaces (mixed real, integer, categorical, and conditional parameters like “if layer X exists, then set parameter Y”).
So, what algorithm can handle all of this efficiently?
The Limitations of Existing Methods
The standard tool for expensive black-box optimization is Bayesian Optimization (BO) using Gaussian Processes (GPs).
GP-based methods (like PESMO, ParEGO, SMS-EGO) are powerful, but they have major drawbacks:
- ❌ Not suitable for non-continuous or conditional (tree-structured) spaces.
- ❌ High computational complexity: O(n³) — they scale poorly with the number of observations.
- ❌ Approximation tricks help but cause performance degradation.
Single-Objective TPE (Tree-Structured Parzen Estimator) is a great alternative that:
- ✅ Naturally handles complex, conditional spaces.
- ✅ Scales to ~1000 observations and tens of variables.
- ✅ Outperforms GP-based methods on single-objective HPO.
- ❌ But: It is designed for single-objective only!
Enter MOTPE: Multiobjective Tree-Structured Parzen Estimator
MOTPE (Ozaki et al., 2020/2022) extends the powerful TPE algorithm to handle multiple objectives. It is designed to be:
| Property | How MOTPE Achieves It |
|---|---|
| Handles complex spaces | Uses Parzen estimators (density estimation) per parameter, not a global GP. |
| Scalable | O(k log k) per iteration vs. O(n³) for GP methods. |
| Parallelizable | Asynchronous parallelization without wait time. |
| Limited budget | Efficiently approximates the Pareto front with few evaluations. |
How It Works: The Core Idea
1. The Split Rule
In single-objective TPE, observations are split into “good” (below a quantile threshold y*) and “bad” (above). For multiple objectives, MOTPE uses a dominance-based split:
- Good set (l(xᵢ)): Points that are either dominated by or incomparable to the current Pareto front approximation Y*.
- Bad set (g(xᵢ)): Points that weakly dominate Y* (i.e., are clearly worse).
This allows the algorithm to learn which parameter values tend to produce good (non-dominated or diverse) solutions.
2. Greedy Splitting with Hypervolume
To select the top γ% of observations for the good set, MOTPE:
- Sorts observations by nondomination rank (Pareto sorting).
- Greedily adds full fronts.
- For the remaining slots, solves the Hypervolume Subset Selection Problem (HSSP) using a greedy algorithm with a (1 — 1/e)-optimality guarantee.
Points in the good set are then weighted by their hypervolume contribution — points that improve the Pareto front more get higher weight in the density model.
3. The Acquisition Function: Expected Hypervolume Improvement (EHVI)
MOTPE uses Expected Hypervolume Improvement (EHVI) as its acquisition function. Remarkably, after derivation, EHVI simplifies to:
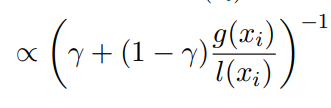
This means: To maximize EHVI, simply maximize the ratio l(xᵢ) / g(xᵢ) — exactly the same as in single-objective TPE! No complex EHVI calculations are needed.
Benchmark Results: How Well Does It Work?
Experiment 1: WFG Benchmark (Low Dimension, Limited Budget)
MOTPE was compared against GP-based methods (PESMO, ParEGO, SMS-EGO) on the WFG test suite with a budget of only 250 evaluations.
Key findings:
- MOTPE achieves comparable or better results on most WFG problems.
- MOTPE is more robust to dimensionality than GP methods.
- Each MOTPE run took minutes; GP runs took hours to days.
Experiment 2: Real-World — CNN Design for CIFAR-10
Task: Design a CNN minimizing two objectives:
- Classification error rate.
- Prediction time (inference speed).
Search space: 13 parameters with complex conditionals (e.g., number of blocks determines which filter parameters are active).
Results:
- ✅ MOTPE outperformed all baselines (ParEGO, SMS-EGO, PESMO, HyperMapper 2.0).
- ✅ MOTPE found a better diversity of trade-offs between accuracy and speed.
- ✅ Baselines tended to find either fast-but-inaccurate or accurate-but-slow models; MOTPE found both.
Key Insights: The Quantile Parameter γ
The γ parameter controls the split between good and bad observations. The paper’s investigation of γ reveals:
| γ value | Effect |
|---|---|
| Small γ (e.g., 0.10) | Stronger pressure to converge to the Pareto front. Better for easy-to-converge problems. |
| Large γ (e.g., 0.40) | Stronger pressure to maintain diversity. Better for biased or hard-to-converge problems. |
Empirical recommendation: Start with γ = 0.10 (the winner in 17 out of 72 experiments).
Asynchronous Parallelization: Practical Speedups
MOTPE supports asynchronous parallelization — workers grab the latest observations, run the algorithm, and evaluate candidates without waiting for others.
Speedup results on WFG4:
- 1 worker → 250 minutes
- 10 workers → 28 minutes
- 30 workers → 13 minutes
On the CNN design problem: Parallelization (4 workers) achieved a ~4x speedup (555 min → 142 min to reach the same hypervolume).
When Should You Use MOTPE?
Use MOTPE when:
- ✅ Your search space has conditional parameters (e.g., neural architecture search).
- ✅ You have a limited evaluation budget (tens to hundreds).
- ✅ You need scalability to many parameters or observations.
- ✅ You want asynchronous parallelization without complicated batching.
Be cautious when:
- ⚠️ The objective space is extremely biased (WFG1 case).
- ⚠️ The problem is highly deceptive (WFG5 case) — but note: GP methods also struggled here.
- ⚠️ You have a very large budget (thousands of evaluations) — evolutionary algorithms like NSGA-II may eventually catch up.
Summary
| Aspect | MOTPE |
|---|---|
| Search space | Tree-structured (mixed types + conditionals) ✅ |
| Scalability | O(k log k) — fast ✅ |
| Parallelization | Asynchronous — no wait time ✅ |
| GP-free | Yes — uses Parzen estimators ✅ |
| Multi-objective | Yes — EHVI-driven ✅ |
| Practical performance | Outperforms GP methods on complex spaces ✅ |
Final Thoughts
MOTPE is a practical, scalable, and effective algorithm for expensive multi-objective optimization in complex, real-world search spaces. If you’re doing neural architecture search, hyperparameter tuning, or any engineering design with multiple objectives and a limited budget, MOTPE deserves a spot in your toolbox.
The algorithm is implemented in Optuna (as MOTPE) and available for use today.
Based on the paper: “Multiobjective Tree-Structured Parzen Estimator” by Ozaki, Tanigaki, Watanabe, Nomura, and Onishi (Journal of Artificial Intelligence Research, 2022).